

Recently the Salesforce team at XCentium ran into case of database history . A legacy system we integrated with predated most modern RDBMS s, and proved to have some interesting challenges.
One of these challenges is the subject of this blog post. To understand the issue, we have to go back a few years.
In 1969 Edgar F. Codd proposed the first model for relational databases. The vast majority of database systems built during the next 50 years were created on the basis of this model. It is by far one of the single most enduring and far ranging concepts in modern IT. Even systems like Salesforce have utilized relational databases extensively.

Over the years certain aspects of Codd s theory have been changed by database vendors.
Backend integration is one of the characteristics that make B2B commerce more complex than B2C. Many organizations run legacy systems that can be challenging to integrate.
To understand our issue, let s look back at E.F. Codd s model, which talks about Primary Keys (PK) on tables.
A PK is used to uniquely identify a record in a table. Codd says: In the relational model of databases, a primary key is a specific choice of a minimal set of attributes (columns) that uniquely specify a tuple (row) in a relation (table). In plain old English he is saying pick those columns in a table that together will uniquely identify a record of the table .
You have to remember Codd s model was created during a time in IT history when storage space was very expensive. The following graph shows how much a 1GB hard drive cost over the years. As you can see, not wasting storage space was an important consideration all the way to the mid 1990 s.
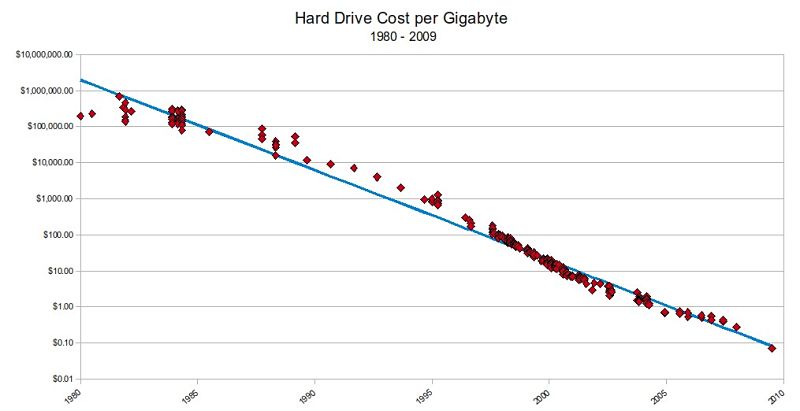
Coincidentally, during the mid to late 1990 s many db vendors released Identity() types a type that automatically increases and never reuses a number. It did not take long for identity() and similar types to become the de-facto standard primary key on tables. As a side-note, without auto incrementing numeric identity columns Ruby on Rails might have gone a different route and not had quite as much success, but that s material for another blog post.
Not long after Identity() came on the scene, db vendors released another tool that assists with Primary Keys the Globally Unique Identifier (GUID). https://en.wikipedia.org/wiki/Universally_unique_identifier
While Identity values are unique for a table, they do repeat in a database and certainly occur again outside of the database. On the other hand, the GUID is globally unique. Many modern systems like to employ GUIDs to assure a given value that identifies a table row is unique anywhere on the current server, the current network or even across the internet with trading partners.
Enough with the history lesson already!
The XCentium Salesforce team was asked to integrate with a legacy system that is housed in an AS400 computer, a platform that has been on rel="noopener noreferrer" the market since 1988! (https://en.wikipedia.org/wiki/IBM_System_i)
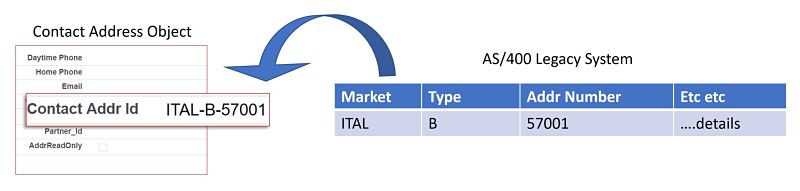
Based on the reasons outlined in our history lesson, we found that data in this system was not identified by one unique value per row. Instead, the tables contained multi-column natural keys that have been set up as primary key. Not one single column to make a record unique.
We certainly could have added any number of additional custom fields to a Salesforce object, but in doing so we would have lost the significance of the data points. After all, in the source system, they were keys. We decided to overcome the dichotomy between systems by storing the multipart primary key as one external Id field in CloudCraze.
The CloudCraze data dictionary offers the following field definition which turned out to be exactly the field we needed:

The external id attribute on a custom field allows the system, especially the data import wizards to take advantage of knowing the row id of the source. In our case, we could not use the baked in goodness of the data wizard functionality, since we had to maintain a conversion step in the integration layer that assembled the address id into one value (among several other ETL tasks). Nonetheless, by taking advantage of this built in field, we can rely on the Salesforce and CloudCraze convention and documentation to make it easy for anyone looking at the Salesforce record to know this specific value of ITAL-B-57001 originated outside of Salesforce.
In summary, when working with legacy systems it helps to know the history of your tools as you never know what request a client is going to throw your way. Thankfully, Cloudcraze anticipates needing to integrate with external systems by providing fields specifically ready to track external key values, even with legacy solutions.